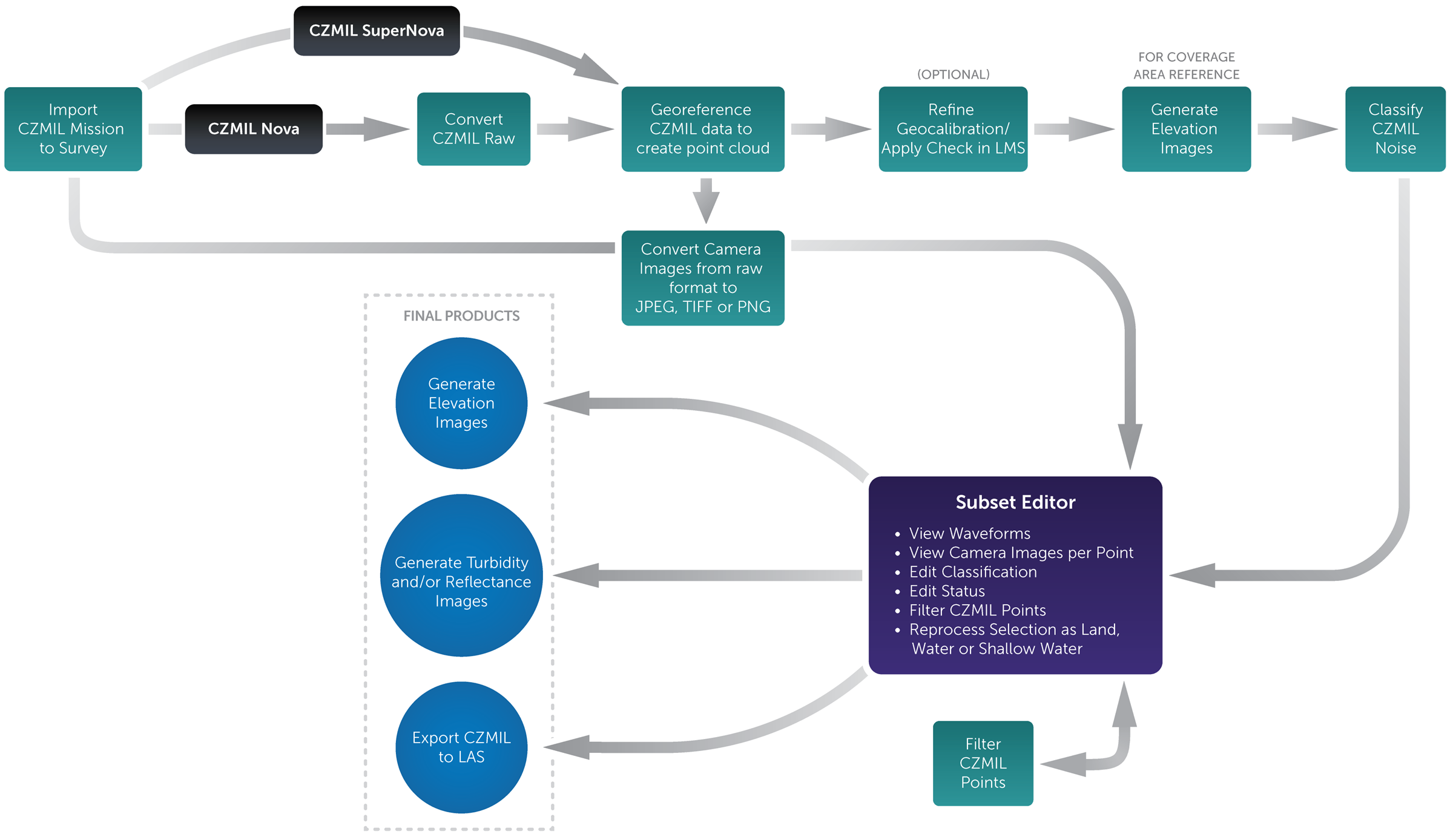
Processing is achieved by applying several processes to the data in a specified order. Each process performs a different, targeted functionality in the CZMIL processing workflow. The processes used to process CZMIL data are provided in the Tools window of BASE Editor. To simplify the running of the processes and to achieve the best outcome, process models have been created and are also available in the Tools window, under a CZMIL category.
Process models are a collection of individual processes that have been chained together to be run as a single process. This allows options to be specified that may not have been available when running a single process. For example, a process model may perform calculations on the data, automatically apply those calculations and generate new outputs from the results. Without a process model, this may have required 3 separate processes to be run. The process model allows the options for all steps to be specified in a single instance and run with a single action. It also ensures the processes are run in the correct order. Process models can also have options pre-populated with values and settings that will give the best results for specific tasks and data types.
Both the processes and/or the process models can be used to process CZMIL data. The CZMIL process models can be run individually, in the order they are listed in the Tools window, or as a one-step process also provided in the Tools window. The processed data can then be analyzed and edited using the Subset Editor provided in BASE Editor.
The CZMIL Nova/SuperNova Workflow is shown below.